1. Naming Convention¶
To avoid confusion with natural naming scheme and the functionality provided by the
trajectory tree - that includes all group and leaf nodes like
parameters and results - I followed the idea by PyTables to use prefixes:
f_ for functions and v_ for python variables/attributes/properties.
For instance, given a result instance myresult, myresult.v_comment is the object’s
comment attribute and
myresult.f_set(mydata=42) is the function for adding data to the result container.
Whereas myresult.mydata might refer to a data item named mydata added by the user.
If you don’t like using prefixes, you can alternatively also use the properties
vars and func that are supported by each tree node. For example,
traj.f_iter_runs() is equivalent to traj.func.iter_runs() or
mygroup.v_full_name is equivalent to mygroup.vars.full_name.
The prefix and vars/func notation only applies to tree data objects
(group nodes and leaf nodes) but
not to other aspects of pypet. For example, the Environment
does not rely on prefixes at all.
Moreover, the following abbreviations are supported by pypet for interaction with a
Trajectory:
confis directly mapped toconfigpartoparametersdpartoderived_parametersrestoresultscrunor the$symbol to the name of the current single run, e.g.run_00000002r_Xandrun_X(e.g.r_8) are mapped to the corresponding run name (e.grun_00000008).rts_Xandruntoset_X(e.g.rts_8) are translated into the corresponding run set for the given run index (e.g.run_set_00000). Note that you need to give the index of the run not the index of the set, e.g.rts_4042givesrun_set_00004.
If you add or request data by using the abbreviations, these are automatically translated into the corresponding long forms.
2. More on Trajectories¶
2.1. Trajectory¶
For some example code on on topics discussed here see the Natural Naming, Storage and Loading script.
The Trajectory is the container for all
results and parameters (see More on Parameters and Results) of your numerical experiments.
Throughout the documentation instantiated objects of the
Trajectory class are usually labeled traj.
Probably you as user want to follow this convention, because writing the not abbreviated expression
trajectory all the time in your code can become a bit annoying after some time.
The trajectory container instantiates a tree with groups and leaf nodes, whereas
the trajectory object itself is the root node of the tree.
There are two types of objects that can be leaves: parameters and results.
Both follow particular APIs (see Parameter and
Result as well as their abstract base classes
BaseParameter, BaseResult).
Every parameters contains a single value and optionally a range of values for exploration.
In contrast, results can contain several heterogeneous data items
(see More on Parameters and Results).
Moreover, a trajectory contains 4 major tree branches:
config(in shortconf)Data stored under config does not specify the outcome of your simulations but only the way how the simulations are carried out. For instance, this might encompass the number of CPU cores for multiprocessing. If you use and generate a trajectory with an environment (More about the Environment), the environment will add some config data to your trajectory.
Any leaf added under config is a
Parameterobject (or descendant of the corresponding base classBaseParameter).As normal parameters, config parameters can only be specified before the actual single runs.
parameters(in shortpar)Parameters are the fundamental building blocks of your simulations. Changing a parameter usually effects the results you obtain in the end. The set of parameters should be complete and sufficient to characterize a simulation. Running a numerical simulation twice with the very same parameter settings should give also the very same results. Therefore, it is recommenced to also incorporate seeds for random number generators in your parameter set.
Any leaf added under parameters is a
Parameterobject (or descendant of the corresponding base classBaseParameter).Parameters can only be introduced to the trajectory before the actual simulation runs.
derived_parameters(in shortdpar)Derived parameters are specifications of your simulations that, as the name says, depend on your original parameters but are still used to carry out your simulation. They are somewhat too premature to be considered as final results. For example, assume a simulation of a neural network, a derived parameter could be the connection matrix specifying how the neurons are linked to each other. Of course, the matrix is completely determined by some parameters, one could think of some kernel parameters and a random seed, but still you actually need the connection matrix to build the final network.
Any leaf added under derived_parameters is a
Parameterobject (or descendant of the corresponding base classBaseParameter).results(in shortres)I guess results are rather self explanatory. Any leaf added under results is a
Resultobject (or descendant of the corresponding base classBaseResult).
Note that all nodes provide the field ‘v_comment’, which can be filled manually or on
construction via comment=. To allow others to understand your simulations it is very
helpful to provide such a comment and explain what your parameter is good for.
2.2. Addition of Groups and Leaves (aka Results and Parameters)¶
Addition of leaves can be achieved via these functions:
Leaves can be added to any group, including the root group, i.e. the trajectory.
Note that if you operate in the parameters subbranch of the tree,
you can only add parameters (i.e. traj.parameters.f_add_parameter(...) but
traj.parameters.f_add_result(...) does not work). For other subbranches
this is analogous.
There are two ways to use the above functions, either you already have an instantiation of the object, i.e. you add a given parameter:
>>> my_param = Parameter('subgroup1.subgroup2.myparam', 42, comment='I am an example')
>>> traj.f_add_parameter(my_param)
Or you let the trajectory create the parameter using your specifications. Note in this case the name is the first positional argument:
>>> traj.f_add_parameter('subgroup1.subgroup2.myparam', 42, comment='I am an example')
There exists a standard constructor that is called in case you let the trajectory create the
parameter. The standard constructor can be changed via the v_standard_parameter property.
Default is the Parameter constructor.
If you only want to add a different type of parameter once, but not change the standard constructor in general, you can add the constructor as the first positional argument followed by the name as the second argument:
>>> traj.f_add_parameter(PickleParameter, 'subgroup1.subgroup2.myparam', data=42, comment='I am an example')
Note that you always should specify a default data value of a parameter, even if you want to explore it later.
Derived parameters, config and results work analogously.
You can sort parameters/results into groups by colons in the names.
For instance, traj.f_add_parameter('traffic.mobiles.ncars', data = 42) creates a parameter
that is added to the subbranch parameters. This will also automatically create
the subgroups traffic and inside there the group mobiles.
If you add the parameter traj.f_add_parameter('traffic.mobiles.ncycles', data = 11) afterwards,
you will find this parameter also in the group traj.parameters.traffic.ncycles.
2.2.1. Caveat of Passing Arguments¶
If you are not interested in some nitty-gritty details, skip this section, but just
remember that for passing comments always use the keyword argument comment=.
Let’s take another look on how pypet actually handles the creation of parameters:
>>> traj.f_add_parameter('subgroup1.subgroup2.myparam', data=42, comment='I am an example')
In this case all arguments and keyword arguments
(here 1 positional and 2 keyword
arguments: 'subgroup1.subgroup2.myparam', data=42, comment='I am an example')
are always passed on to the Parameter constructor as you provide them.
So internally pypet just calls
Parameter('subgroup1.subgroup2.myparam', data=42, comment='I am an example').
For parameters, the keyword arguments data= and comment= are optional.
You could instead be using positional arguments, as in:
>>> traj.f_add_parameter('subgroup1.subgroup2.myparam', 42, 'I am an example')
Internally pypet calls
Parameter('subgroup1.subgroup2.myparam', 42, 'I am an example') which is equivalent to
the keyword argument version
Parameter('subgroup1.subgroup2.myparam', data=42, comment='I am an example').
Note that we also got rid of the comment= keyword. But you are advised
to always use the keyword argument comment= if you want to provide a comment.
Leaving it out does not work for results.
To stress this again,
for results you cannot leave out the keyword argument ``comment=``if you want to provide a comment.
The reason is that results can keep more than a single data item; as we will see later.
So here the keyword argument comment= is necessary to stress that the string you provide
is indeed a comment and not just data.
>>> traj.f_add_result('myresult', 125, comment='I am an example result')
is not equivalent to
>>> traj.f_add_result('myresult', 125, 'I am an example result')
because in the first case 'I am an example result' is a comment, whereas in the
second 'I am an example result' is interpreted as a data item.
2.2.2. More Ways to Add Data¶
Moreover, for each of the adding functions there exists a shorter abbreviation that spares you typing:
Besides these functions, pypet gives you the possibility to add new leaves via generic attribute setting.
For example, you could also add a parameter (or result) as follows:
>>> traj.parameters.myparam = Parameter('myparam', 42, comment='I am a useful comment!')
Which creates a novel parameter myparam under traj.parameters.
It is important how you choose the name of your parameter or result.
If the names match (.myparam and 'myparam') as above,
or if your parameter has the empty string as a name
(traj.parameters.myparam = Parameter('', 42)), the parameter will be added
and named as the generic attribute, here myparam.
However, if the names disagree an AttributeError is thrown.
Yet, you can still create groups on the fly
>>> traj.parameters.mygroup = Parameter('mygroup.mysubgroup.myparam', 42)
- creates a new parameter at
traj.parameters.mygroup.mysubgroup.myparamandmygroupand mysubgroupare new group nodes, respectively.
The different ways of adding data are also explained in example Adding Data to the Trajectory.
2.2.3. Group Nodes¶
Besides leaves you can also add empty groups to the trajectory (and to all subgroups, of course) via:
As before, if you create the group groupA.groupB.groupC and
if group A and B were non-existent before, they will be created on the way.
Note that pypet distinguishes between three different types of name descriptions,
the full name of a node which would be,
for instance, parameters.groupA.groupB.myparam, the (short) name myparam and the
location within the tree, i.e. parameters.groupA.groupB.
All these properties are accessible for each group and
leaf via:
v_full_namev_locationv_name
Location and full name are relative to the root node. Since a trajectory object
is the root of the tree, its full_name is '', the empty string.
Yet, the name property is not empty
but contains the user chosen name of the trajectory.
Note that if you add a parameter/result/group with f_add_XXXXXX
the full name will be extended by the full name of the group you added it to:
>>> traj.parameters.traffic.f_add_parameter('street.nzebras')
The full name of the new parameter is going to be parameters.traffic.street.nzebras.
If you add anything directly to the root group, i.e. the trajectory,
the group names parameters, config, derived_parameters will be automatically added
(of course, depending on what you add, config, a parameter etc.).
If you add a result or derived parameter during a single run, the name will be changed to include the current name of the run.
For instance, if you add a result during a single run (let’s assume it’s the first run) like
traj.f_add_result('mygroup.myresult', 42, comment='An important result'),
the result will be renamed to results.runs.run_00000000.mygroup.myresult.
Accordingly, all results (and derived parameters) of all runs are stored into different
parts of the tree and are kept independent.
If this sorting does not really suit you, and you don’t want your results and derived
parameters to be put in the sub-branches runs.run_XXXXXXXXX (with XXXXXXXX the index of the
current run), you can make use of the wildcard character '$'.
If you add this character to the name of your new result or derived parameter, pypet
will automatically replace this wildcard character with the name of the current run.
For instance, if you add a result during a single run (let’s assume again the first one)
via traj.f_add_result('mygroup.$.myresult', 42, comment='An important result')
the result will be renamed to results.mygroup.run_00000000.myresult.
Thus, the branching of your tree happens on a lower level than before.
Even traj.f_add_result('mygroup.mygroup.$', myresult=42, comment='An important result')
is allowed.
You can also use the wildcard character in the preprocessing stage. Let’s assume you add
the following derived parameter before the actual single runs via
traj.f_add_derived_parameter('mygroup.$.myparam', 42, comment='An important parameter').
If that happend during a single run '$' would be renamed to run_XXXXXXXX (with XXXXXXXX
the index of the run). Yet, if you add the parameter BEFORE the single runs,
'$' will be replaced by the placeholder name run_ALL.
So your new derived parameter here is now called mygroup.run_All.myparam.
Why is this useful?
Well, this is in particular useful if you pre-compute derived parameters before the single runs which depend on parameters that might be explored in the near future.
For example you have parameter seed and n and which you use to draw a vector of random numbers.
You keep this vector as a derived parameter. As long as you do not explore different
seeds or values of n you can compute the random numbers before the single runs
to save time. Now, if you use the '$' statement right from the beginning it would not make
a difference if the following statement was executed during the pre-processing stage
or during the single runs:
np.random.seed(traj.parameters.seed)
traj.f_add_derived_parameter('random_vector.$', np.random(traj.paramaters.n))
In both cases during the single run, you can access your data via traj.dpar.random_vector.crun
and pypet will return the data regardless when you added the derived parameter. Internally pypet
tries to resolve traj.dpar.random_vector.run_XXXXXXXX (with run_XXXXXXXXX referring
to the current run, like run_00000002) first. If this fails, it will fall back to
traj.dpar.random_vector.run_ALL (if this fails, too, pypet will throw an error).
Accordingly, you have to write less code and post-processing and data analysis become easier.
2.2.4. No Clobber¶
You can set traj.v_no_clobber=True to ignore the addition of existing data.
In this case adding an already existing item to your trajectory won’t throw an
AttributeError but simply ignore your addition:
>>> traj.f_add_parameter('testparam', 42)
>>> traj.v_no_clobber=True
>>> traj.f_add_parameter('testparam', 39)
>>> traj.par.testparam
42
2.2.5. More on Wildcards¶
So far we have seen that the ‘$’ wildcard translates into the current run name.
Similarly does crun.
So, traj.res.runs['$'].myresult is equivalent to traj.res.runs.crun.myresult.
By default, there exists another wildcard called ‘$set’ or crunset. Both translate to
grouping of results into buckets of 1000 runs. More precisely, they are translated to
run_set_XXXXX where XXXXX is just the set number. So the first 1000 runs are translated
into run_set_00000, the next 1000 into run_set_00001 and so on.
Why is this useful? Well, if you perform many runs, more than 10,000, HDF5 becomes rather slow, because it cannot handle nodes with so many children. Grouping your results into buckets simply overcomes this problem. Accordingly, you could add a result as:
>>> traj.f_add_result('$set.$.myresult', 42)
And all results will be sorted into groups of 1000 runs, like
traj.results.run_set_00002.run_00002022 for run 2022.
This is also shown in Large Explorations with Many Runs.
Moreover, you can actually define your own wildcards or even replace the existing ones.
When creating a trajectory you can pass particular wildcard functions via wildcard_functions.
This has to be a dictionary containing tuples of wildcards like ('$', 'crun) as keys and
translation functions as values. The function needs to take a single argument, that is the
current run index and resolve it into a name. So it must handle all integers of 0 and larger.
Moreover, it must also handle -1 to create a dummy name. For instance, you could define
your own naming scheme via:
from pypet import Trajectory
def my_run_names(idx):
return 'this_is_run_%d' % d
my_wildcards = {('$', 'crun'): my_run_names}
traj = Trajectory(wildcard_functions=my_wildcards)
Now calling traj.f_add_result('mygroup.$.myresult', 42) during a run, translates into
traj.mygroup.this_is_run_7 for index 7.
There’s basically no constrain on the wildcard functions, except for the one defining (‘$’, ‘crun’) because it has to return a unique name for every integer from -1 to infinity. However, other wildcards can be more open and group many runs together:
from pypet import Trajectory
def my_run_names(idx):
return 'this_is_run_%d' % d
def my_group_names(idx):
if idx == -1:
return 'dummy_group'
elif idx < 9000:
return 'smaller_than_9000'
else:
return 'over_9000'
my_wildcards = {('$', 'crun'): my_run_names,
('$mygrouping', 'mygrouping'): my_group_names}
traj = Trajectory(wildcard_functions=my_wildcards)
Thus, traj.f_add_result(‘mygroup.$mygrouping.$.myresult’, 42)` would translate into
traj.results.mygroup.over_9000.this_is_run_9009 for run 9009.``
2.2.6. Generic Addition¶
You do not have to stick to the given trajectory structure with its four subtrees:
config, parameters, derived_parameters, results. If you just want to use a trajectory
as a simple tree container and store groups and leaves wherever you like, you can use the
generic functions f_add_group() and
f_add_leaf(). Note however, that the four subtrees are
reserved. Thus, if you add anything below one of the four, the corresponding
speciality functions from above are called instead of the generic ones.
2.3. Accessing Data in the Trajectory¶
To access data that you have put into your trajectory you can use
f_get()method. You might want to take a look at the function definition to check out the other arguments you can pass tof_get.f_getnot only works for the trajectory object, but for any group node in your tree.- Use natural naming dot notation like
traj.nzebras. This natural naming scheme supports some special features see below. - Use the square brackets - as you do with dictionaries - like
traj['nzebras']which is equivalent to callingtraj.nzebras.
2.3.1. Natural Naming¶
As said before trajectories instantiate trees and the tree can be browsed via natural naming.
For instance, if you add a parameter via traj.f_add_parameter('traffic.street.nzebras', data=4),
you can access it via
>>> traj.parameters.street.nzebras
4
Here comes also the concept of fast access. Instead of the parameter object you directly
access the data value 4.
Whether or not you want fast access is determined by the value of
v_fast_access (default is True):
>>> traj.v_fast_access = False
>>> traj.parameters.street.nzebras
<Parameter object>
Note that fast access works for parameter objects (i.e. for everything you store under parameters,
derived_parameters, and config) that are non empty. If you say for instance traj.x and x
is an empty parameter, you will get in return the parameter object. Fast access works
in one particular case also for results, and that is, if the result contains exactly one item
with the name of the result.
For instance, if you add the result traj.f_add_result('z', 42), you can fast access it, since
the first positional argument is mapped to the name ‘z’ (See also Results).
If the result container is empty or contains more than one item,
you will always get in return the result object.
>>> traj.f_add_result('z', 42)
>>> traj.z
42
>>> traj.f_add_result('k', kay=42)
>>> traj.k
<Result object>
>>> traj.k.kay
42
>>> traj.f_add_result('two_data_values', 11, 12.0)
>>> traj.two_data_values
<Result object>
>>> traj.two_data_values[0]
11
2.3.2. Shortcuts¶
As a user you are encouraged to nicely group and structure your results as fine grain as possible. Yet, you might think that you will inevitably have to type a lot of names and colons to access your values and always state the full name of an item. This is, however, not true. There are two ways to work around that. First, you can request the group above the parameters, and then access the variables one by one:
>>> mobiles = traj.parameters.traffic.mobiles
>>> mobiles.ncars
42
>>> mobiles.ncycles
11
Or you can make use of shortcuts. If you leave out intermediate groups in your natural naming request, a breadth first search is applied to find the corresponding group/leaf.
>>> traj.mobiles
42
>>> traj.traffic.mobiles
42
>>> traj.parameters.ncycles
11
Search is established with very fast look up and usually needs much less then 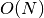 [most often
[most often 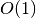 or
or 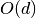 , where
, where 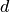 is the depth of the tree
and N the total number of nodes, i.e. groups + leaves].
is the depth of the tree
and N the total number of nodes, i.e. groups + leaves].
However, sometimes your shortcuts are not unique and you might find several solutions for
your natural naming search in the tree. pypet will return the first item it finds via breadth
first search within the tree. If there are several items with the same name but in different
depths within the tree, the one with the lowest depth is returned. For performance reasons
pypet actually stops the search if an item was found and there is no other item within the tree
with the same name and same depth. If there happen to be
two or more items with the same name and with the same depth in the tree, pypet will
raise a NotUniqueNodeError since pypet cannot know which of the two items you want.
The method that performs the natural naming search in the tree can be called directly, it is
f_get().
>>> traj.parameters.f_get('mobiles.ncars')
<Parameter object ncars>
>>> traj.parameters.f_get('mobiles.ncars', fast_access=True)
42
If you don’t want to allow this shortcutting through the tree use f_get(target, shortcuts=False)
or set the trajectory attribute v_shortcuts=False to forbid the shortcuts for natural naming
and getitem access.
As a remainder, there also exist nice naming shortcuts for already present groups (these are always active and cannot be switched off):
- par is mapped to parameters, i.e.
traj.parametersis the same group astraj.par - dpar is mapped to derived_parameters
- res is mapped to results
- conf is mapped to config
- crun is mapped to the name of the current run (for example run_00000002)
- r_X and run_X are mapped to the corresponding run name, e.g. r_3 is mapped to run_00000003
For instance, traj.par.traffic.street.nzebras is equivalent to
traj.parameters.traffic.street.nzebras.
2.4. Links¶
Although each node in the trajectory tree is identified by a unique full name, there can potentially many paths to a particular node established via links.
One can add a link to every group node simply via
f_add_link().
For instance:
>>> traj.parameters.f_add_link('mylink', traj.f_get('x'))
Thus, traj.mylink now points to the same data as traj.x.
Colon separated names are not allowed for links, i.e.
traj.parameters.f_add_link('mygroup.mylink', traj.f_get('x')) does not work.
Links can also be created via generic attribute setting:
>>> traj.mylink2 = traj.f_get('x')
See also the example Using Links.
Links will be handled as normal children during interaction with the trajectory.
For example, using f_iter_nodes() with recursive=True
will also recursively iterate all linked groups and leaves. Moreover, pypet takes care
that all nodes are only visited once. To skip linked nodes simply set with_links=False.
However, for storage and loading (see below) links are never evaluated recursively.
Even setting recursive=True linked nodes are, of course,
stored or loaded but not their children.
2.5. Parameter Exploration¶
Exploration can be prepared with the function f_explore().
This function takes a dictionary with parameter names
(not necessarily the full names, they are searched) as keys and iterables specifying
the parameter ranges as values. Note that all iterables
need to be of the same length. For example:
>>> traj.f_explore({'ncars':[42,44,45,46], 'ncycles' :[1,4,6,6]})
This would create a trajectory of length 4 and explore the four parameter space points
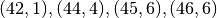 . If you want to explore the cartesian product of
parameter ranges, you can take a look
at the
. If you want to explore the cartesian product of
parameter ranges, you can take a look
at the cartesian_product() function.
You can extend or expand an already explored trajectory to explore the parameter space further with
the function f_expand().
2.5.1. Using Numpy Iterables¶
Since parameters are very conservative regarding the data they accept (see Values supported by Parameters), you sometimes won’t be able to use Numpy arrays for exploration as iterables.
For instance, the following code snippet won’t work:
import numpy a np
from pypet.trajectory import Trajectory
traj = Trajectory()
traj.f_add_parameter('my_float_parameter', 42.4, comment='My value is a standard python float')
traj.f_explore( { 'my_float_parameter': np.arange(42.0, 44.876, 0.23) } )
This will result in a TypeError because your exploration iterable np.arange(42.0, 44.876, 0.23)
contains numpy.float64 values whereas you parameter is supposed to use standard python floats.
Yet, you can use numpy’s tolist() function to overcome this problem:
traj.f_explore( { 'my_float_parameter': np.arange(42.0, 44.876, 0.23).tolist() } )
Or you could specify your parameter directly as a numpy float:
traj.f_add_parameter('my_float_parameter', np.float64(42.4),
comment='My value is a numpy 64 bit float')
2.6. Presetting of Parameters¶
I suggest that before you calculate any results or derived parameters, you should define all parameters used during your simulations. Usually you could do this by parsing a config file, or simply by executing some sort of a config python script that simply adds the parameters to your trajectory (see also Tutorial).
If you have some complex simulations where you might use only parts of your parameters or
you want to exclude a set of parameters and include some others, you can make use
of the presetting of parameters (see f_preset_parameter()).
This allows you to add control flow on the setting or parameters. Let’s consider an example:
traj.f_add_parameter('traffic.mobiles.add_cars', True , comment='Whether to add some cars or '
'bicycles in the traffic simulation')
if traj.add_cars:
traj.f_add_parameter('traffic.mobiles.ncars', 42, comment='Number of cars in Rome')
else:
traj.f_add_parameter('traffic.mobiles.ncycles', 13, comment'Number of bikes, in case '
'there are no cars')
There you have some control flow. If the variable add_cars is True, you will add
42 cars otherwise 13 bikes. Yet, by your definition one line before add_cars
will always be True.
To switch between the use cases you can rely on presetting
of parameters. If you have the following statement somewhere before in your main function,
you can make the trajectory change the value of add_cars right after the parameter was
added:
traj.f_preset_parameter('traffic.mobiles.add_cars', False)
So when it comes to the execution of the first line in example above, i.e.
traj.f_add_parameter('traffic.mobiles.add_cars', True , comment='Whether to add some cars or bicycles in the traffic simulation'),
the parameter will be added with the default value add_cars=True but immediately afterwards
the f_set() function will be called with the value
False. Accordingly, if traj.add_cars: will evaluate to False and the bicycles will be added.
In order to preset a parameter you need to state its full name (except the prefix
parameters) and you cannot shortcut through the tree. Don’t worry about typos, before the running
of your simulations it will be checked if all parameters marked for presetting were reached,
if not a PresettingError will be thrown.
2.7. Storing¶
Storage of the trajectory container and all it’s content is not carried out by the
trajectory itself but by a service. The service is known to the trajectory and can be
changed via the v_storage_service property.
The standard storage service (and the only one
so far, you don’t bother write an SQL one? :-) is the
HDF5StorageService.
As a side remark, if you create a trajectory on your own (for loading)
with the Trajectory class
constructor and you pass it a filename, the trajectory will create an
HDF5StorageService operating on that file for you.
You don’t have to interact with the service directly, storage can be initiated by several methods of the trajectory and it’s groups and subbranches (they format and hand over the request to the service).
The most straightforward way to store everything is to say:
>>> traj.f_store()
and that’s it. In fact, if you use the trajectory in combination with the environment (see More about the Environment) you do not need to do this call by yourself at all, this is done by the environment.
If you store a trajectory to disk it’s tree structure is also found in the structure of
the HDF5 file!
In addition, there will be some overview tables summarizing what you stored into the HDF5 file.
They can be found under the top-group overview, the different tables are listed in the
HDF5 Overview Tables section.
By the way, you can switch the creation of these tables off passing the appropriate arguments to the
Environment constructor to reduce the size of the final HDF5 file.
There are four different storage modes that can be chosen for f_store(store_data=2) and
the store_data keyword argument (default is 2).
pypet.pypetconstants.STORE_NOTHING: (0)Nothing is stored, basically a no-op.
pypet.pypetconstants.STORE_DATA_SKIPPING: (1)A speedy version of the choice below. Data of nodes that have not been stored before are written to disk. Thus, skips all nodes (groups and leaves) that have been stored before, even if they contain new data that has not been stored before.
pypet.pypetconstants.STORE_DATA: (2)Stores data of groups and leaves to disk. Note that individual data already found on disk is not overwritten. If leaves or groups contain new data that is not found on disk, the new data is added. Here addition only means creation of new data items like tables and arrays, but data is not appended to existing data arrays or tables.
pypet.pypetconstants.OVERWRITE_DATA: (3)Stores data of groups and leaves to disk. All data on disk is overwritten with data found in RAM. Be aware that this may yield fragmented HDF5 files. Therefore, use with care. Overwriting data is not recommended as explained below.
Although you can delete or overwrite data you should try to stick to this general scheme: Whatever is stored to disk is the ground truth and, therefore, should not be changed.
Why being so strict? Well, first of all, if you do simulations, they are like numerical scientific experiments, so you run them, collect your data and keep these results. There is usually no need to modify the first raw data after collecting it. You may analyse it and create novel results from the raw data, but you usually should have no incentive to modify your original raw data. Second of all, HDF5 is bad for modifying data which usually leads to fragmented HDF5 files and does not free memory on your hard drive. So there are already constraints by the file system used (but trust me this is minor compared to the awesome advantages of using HDF5, and as I said, why the heck do you wanna change your results, anyway?).
Again, in case you use your trajectory with or via an Environment
there is no need to call f_store()
for data storage, this will always be called at the end of the simulation and at the end of a
single run automatically (unless you set automatic_storing to False).
Yet, be aware that if you add any custom data during a single run not under a group or leaf with
run_XXXXXXXX in their full name this data will not
be immediately saved after the completion of the run. In fact,
in case of multiprocessing this data will be lost if not manually stored.
2.7.1. Storing data individually¶
Assume you computed a result that is extremely large. So you want to store it to disk, than free the result and forget about it for the rest of your simulation or single run:
>>> large_result = traj.results.f_get('large_result')
>>> traj.f_store_item(large_result)
>>> large_result.f_empty()
Note that in order to allow storage of single items, you need to have stored the trajectory at
least once. If you operate during a single run, this has been done before, if not,
simply call traj.f_store() once before. If you do not want to store anything but initialise
the storage, you can pass the argument only_init=True, i.e. traj.f_store(only_init=True).
Moreover, if you call f_empty() on a large result,
only the reference to the giant data block within the result is deleted.
So in order to make the python garbage collector free the memory, you must
ensure that you do not have any external reference of your own in your code to the giant data.
To avoid re-opening an closing of the HDF5 file over and over again there is also the
possibility to store a list of items via f_store_items()
or whole subtrees via f_store_child() or
f_store().
Keep in mind that Links are always stored non-recursively
despite the setting of recursive in these functions.
2.8. Loading¶
Sometimes you start your session not running an experiment, but loading an old trajectory.
You can use the load_trajectory() function or create a new empty trajectory
and use the trajectory’s f_load() function. In both
cases you should to pass a filename referring to your HDF5 file.
Moreover, pass a name or an index of the trajectory
you want to select within the HDF5 file.
For the index you can also count backwards, so
-1 would yield the last or newest trajectory in an HDF5 file.
There are two different loading schemes depending on the argument as_new
as_new=TrueYou load an old trajectory into your current one, and only load everything stored under parameters in order to rerun an old experiment. You could hand this loaded trajectory over to an
Environmentand carry out another the simulation again.as_new=FalseYou want to load and old trajectory and analyse results you have obtained. If using the trajectory’s
f_load()method, the current name of the trajectory will be changed to the name of the loaded one.
If you choose the latter load mode, you can specify how the individual subtrees config, parameters, derived_parameters, and results are loaded:
pypet.pypetconstants.LOAD_NOTHING: (0)Nothing is loaded, just a no-op.
pypet.pypetconstants.LOAD_SKELETON: (1)The skeleton is loaded including annotations (See Annotations). This means that only empty parameter and result objects will be created and you can manually load the data into them afterwards. Note that
pypet.annotations.Annotationsdo not count as data and they will be loaded because they are assumed to be small.pypet.pypetconstants.LOAD_DATA: (2)The whole data is loaded. Note in case you have non-empty leaves already in your trajectory, these are left untouched.
pypet.pypetconstants.OVERWRITE_DATA: (3)As before, but non-empty nodes are emptied and reloaded.
Compared to manual storage, you can also load single items manually via
f_load_item(). If you load a large result with many entries
you might consider loading only parts of it (see f_load_items())
In order to load a parameter, result, or group, with
f_load_item() it must exist in the current trajectory in RAM,
if it does not you can always bring your skeleton of your trajectory tree up to date
with f_update_skeleton(). This will load all items stored
to disk and create empty instances. After a simulation is completed, you need to call this function
to get the whole trajectory tree containing all new results and derived parameters.
And last but not least, there are also f_load_child() or
f_load() methods in order to load whole subtrees.
Keep in mind that links (Links) are always loaded non-recursively
despite the setting of recursive in these functions.
2.8.1. Automatic Loading¶
The trajectory supports the nice feature to automatically loading data while you access it.
Set traj.v_auto_load=True and you don’t have to care about loading at all during data analysis.
Enabling automatic loading will make pypet do two things. If you try to access group nodes or leaf nodes that are currently not in your trajectory on RAM but stored to disk, it will load these with data. Note that in order to automatically load data you cannot use shortcuts! Secondly, if your trajectory comes across an empty leaf node, it will load the data from disk (here shortcuts work again, since only data and not the skeleton has to be loaded).
For instance:
# Create the trajectory independent of the environment
traj = Trajectory(filename='./myfile.hdf5')
# We add a result
traj.f_add_result('mygropA.mygroupB.myresult', 42, comment='The answer')
# Now we store our trajectory
traj.f_store()
# We remove all results
traj.f_remove_child('results', recursive=True)
# We turn auto loading on
traj.v_auto_loading = True
# Now we can happily recall the result, since it is loaded while we access it.
# Stating `results` here is important. We removed the results node above, so
# we have to explicitly name it here to reload it, too. There are no shortcuts allowed
# for nodes that have to be loaded on the fly and that did not exist in memory before.
answer= traj.results.mygroupA.mygroupB.myresult
# And answer will be 42
# Ok next example, now we only remove the data. Since everything is loaded we can shortcut
# through the tree.
traj.f_get('myresult').f_empty()
# Btw we have to use `f_get` here to get the result itself and not the data `42` via fast
# access
# If we now access `myresult` again through the trajectory, it will be automatically loaded.
# Since the result itself is still in RAM but empty, we can shortcut through the tree:
answer = traj.myresult
# And again the answer will be 42
2.8.2. Logging and Git Commits during Data Analysis¶
Automated logging and git commits are often very handy features. Probably you do not want
to miss these while you do your data analysis. To enable these in case you simply want to
load an old trajectory for data analysis without doing any more single runs, you can
again use an Environment.
First, load the trajectory with f_load(),
and pass the loaded trajectory to a new environment. Accordingly, the environment will trigger a
git commit (in case you have specified a path to your repository root) and enable logging.
You can additionally pass the argument do_single_runs=False to your environment if you only
load your trajectory for data analysis. Accordingly, no config information like
whether you want to use multiprocessing or resume a broken experiment is added to
your trajectory. For example:
# Create the trajectory independent of the environment
traj = Trajectory(filename='./myfile.hdf5',
dynamic_imports=[BrianParameter,
BrianMonitorResult,
BrianResult])
# Load the first trajectory in the file
traj.f_load(index=0, load_parameters=2,
load_derived_parameters=2, load_results=1,
load_other_data=1)
# Just pass the trajectory as the first argument to a new environment.
# You can pass the usual arguments for logging and git integration.
env = Environment(traj
log_folder='./logs/',
git_repository='../gitroot/',
do_single_runs=False)
# Here comes your data analysis...
2.9. Removal of items¶
If you only want to remove items from RAM (after storing them to disk),
you can get rid of whole subbranches via f_remove_child().
f_remove().
But usually it is enough to simply free the data and keep empty results by using
the f_empty() function of a result or parameter. This will leave the actual skeleton
of the trajectory untouched.
Although I made it pretty clear that in general what is stored to disk should be set in stone,
there are a functions to delete items not only from RAM but also from disk:
f_delete_item() and
f_delete_items().
Note that you cannot delete explored parameters.
2.10. Merging and Backup¶
You can backup a trajectory with the function f_backup().
If you have two trajectories that live in the same space you can merge them into one
via f_merge().
There are a variety of options how to merge them. You can even discard parameter space points
that are equal in both trajectories. You can simply add more trials to a given trajectory
if both contain a trial parameter. This is an integer parameter that simply runs from
0 to N1-1 and 0 to N2-1 with N1 trials in your current and N2 trials in the other
trajectory, respectively. After merging the trial parameter in your
merged trajectory runs from 0 to N1+N2-1.
Also checkout the example in Merging of Trajectories.
Moreover, if you need to merge several trajectories take a look at the faster
f_merge_many() function.
2.11. Single Runs¶
A single run of your simulation function is identified by it’s index and position in your trajectory,
you can access this via v_idx of your trajectory.
As a proper informatics nerd, if you have N runs, than your first run’s index is 0
and the last is indexed as N-1! Also each run has a name run_XXXXXXXX where XXXXXXXX is the
index of the run with some leading zeros, like run_00000007. You can access the name
via the v_crun property.
During the execution of individual runs the functionality of your trajectory is reduced:
- You can no longer add data to config and parameters branch
- You can usually not access the full exploration range of parameters but only the current value that corresponds to the index of the run.
- Some functions like
f_explore()are no longer supported.
Conceptually one should regard all single runs to be independent. As a consequence, you should not load data during a particular run that was computed by a previous one. You should not manipulate data in the trajectory that was not added during the particular single run. This is very important! When it comes to multiprocessing, manipulating data put into the trajectory before the single runs is useless. Because the trajectory is either pickled or the whole memory space of the trajectory is forked by the OS, changing stuff within the trajectory will not be noticed by any other process or even the main script!
3. Interaction with Trajectories after an Experiment¶
3.1. Iterating over Loaded Data in a Trajectory¶
The trajectory offers a way to iteratively look into the data you have obtained from several runs.
Assume you have computed the value z with z=traj.x*traj.x and added z to the trajectory
in each run via traj.f_add_result('z', z). Accordingly, you can find a couple of
traj.results.runs.run_XXXXXXXX.z in your trajectory (where XXXXXXXX is the index
of a particular run like 00000003). To access these one after the other it
is quite tedious to write run_XXXXXXXX each time.
There is a way to tell the trajectory
to only consider the subbranches that are associated with a single run and blind out everything else.
You can use the function f_set_crun() to make the
trajectory only consider a particular run (it accepts run indices as well as names).
Alternatively, you can set the run idx via changing
v_idx of your trajectory object.
In order to set everything back to normal call f_restore_default()
or set v_idx to -1.
For example, consider your trajectory contains the parameters x and y and both have been
explored with 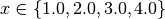 and
and 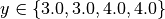 and
their product is stored as z. The following
code snippet will iterate over all four runs and print the result of each run:
and
their product is stored as z. The following
code snippet will iterate over all four runs and print the result of each run:
for run_name in traj.f_get_run_names():
traj.f_set_crun(run_name)
x=traj.x
y=traj.y
z=traj.z
print('%s: x=%f, y=%f, z=%f' % (run_name,x,y,z))
# Don't forget to reset your trajectory to the default settings, to release its belief to
# be the last run:
traj.f_restore_default()
This will print the following statement:
run_00000000: x=1.000000, y=3.000000, z=3.000000
run_00000001: x=2.000000, y=3.000000, z=6.000000
run_00000002: x=3.000000, y=4.000000, z=12.000000
run_00000003: x=4.000000, y=4.000000, z=16.000000
To see this in action you might want to check out Merging of Trajectories.
3.2. Looking for Subsets of Parameter Combinations (f_find_idx)¶
Let’s say you already explored the parameter space and gathered some results.
The next step would be to post-process and analyse the results. Yet, you are not
interested in all results at the moment but only for subsets where the parameters
have certain values. You can find the corresponding run indices with the
f_find_idx() function.
In order to filter for particular settings you need a lambda filter function and a list specifying the names of the parameters that you want to filter. You don’t know what lambda functions are? You might wanna read about it in Dive Into Python.
For instance, let’s assume we explored the parameters ‘x’ and ‘y’ and the cartesian product
of 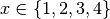 and
and 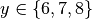 . We want to know the run indices for
. We want to know the run indices for
x==2 or y==8. First we need to formulate a lambda filter function:
>>> my_filter_function = lambda x,y: x==2 or y==8
Next we can ask the trajectory to return an iterator (in fact it’s a generator) over all run indices that fulfil the above named condition:
>>> idx_iterator = traj.f_find_idx(['parameters.x', 'parameters.y'], my_filter_function)
Note the list ['parameters.x', 'parameters.y'] to tell the trajectory which parameters are
associated with the variables in the lambda function. Make sure they are in the same order as
in your lambda function.
Now if we print the indexes found by the lambda filter, we get:
>>> print([idx for idx in idx_iterator])
[1, 5, 8, 9, 10, 11]
To see this in action check out Using the f_find_idx Function.
4. Annotations¶
Annotations are a small extra feature. Every group node
(including your trajectory root node) and every leaf has a property called
v_annotations.
These are other container objects (accessible via natural naming of course),
where you can put whatever you want! So you can mark your items in a specific way
beyond simple comments:
>>> ncars_obj = traj.f_get('ncars')
>>> ncars_obj.v_annotations.my_special_annotation = ['peter','paul','mary']
>>> print(ncars_obj.v_annotations.my_special_annotation)
['peter','paul','mary']
So here you added a list of strings as an annotation called my_special_annotation. These annotations map one to one to the attributes of your HDF5 nodes in your final hdf5 file. The high flexibility of annotating your items comes with the downside that storage and retrieval of annotations from the HDF5 file is very slow. Hence, only use short and small annotations. Consider annotations as a neat additional feature, but I don’t recommend using the annotations for large machine written stuff or storing large result like data (use the regular result objects to do that).